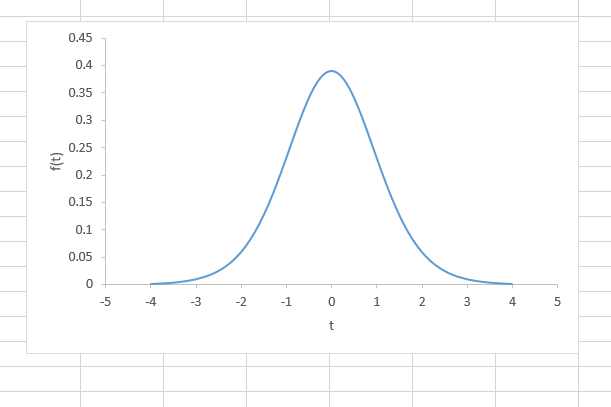
t-분포는 연속 확률분포의 한 종류다. t-분포의 성질은 아래와 같다. 연속적이다. 종모양(bell-shaped)이다. '0'에서 대칭(symmetry)이다. 자유도 하나의 파마미터로 정의된다. 자유도(degrees of freedom)가 무한대(infite)로 갈수록 t-분포는 정규분포(normal distribution)에 수렴한다. t-분포는 표본의 크기가 크지 않은(n 차트 > 분산형(곡선이 있는 분산형)을 선택한다. 5. 그래프를 예쁘게 데코 한다. 그래프에서 x축 라인 값을 더블클릭하고 세로축 교차에서 축 값을 -5로 변경 그래프를 클릭하고 우측 상단에 나오는 '+'를 선택하여 차트 제목 제거, 축 이름 x-t, y-f(t)로 하고, 표시선을 제거할 수 있다. 여러 개의 t-분포 그래프 겹쳐 ..