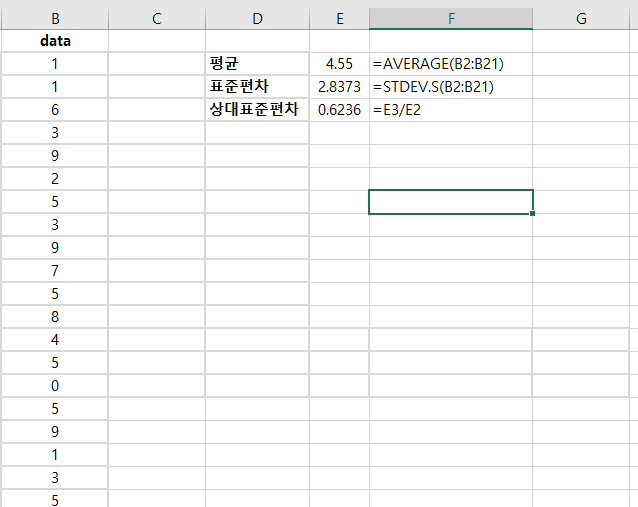
상대표준편차(Relatie Standard Deviation)는 표본 집단(Sample)의 평균(mean)에 대비해서 표본의 표준편차(Standard Deviation)을 측정한다. 상대표준편차(Relative standard deviation) = s / x * 100% s: 표본 표준편차 x: 표본 평균 상대표준편차(Relative standard deviation)로 데이터값들이 평균(mean)에 얼마만큼 밀집되어 있는지 볼 수 있다. 예를들어 표준편차 4, 평균 400이면, 상대표준편차(relative standard deviation)은 4/400*100% = 1%다. 이 수치가 작으면 작을 수록 더 평균에 값들이 밀집해있다. 만약, 표준편차 40, 평균 400이면, 상대표준편차(relative..