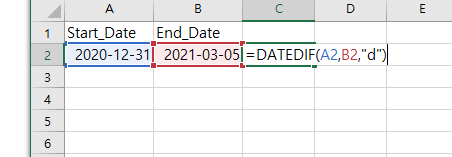
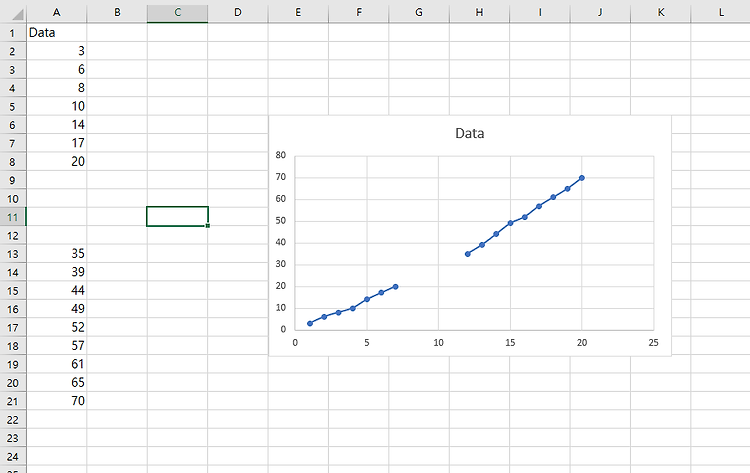
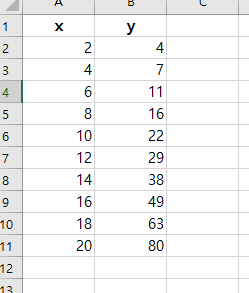
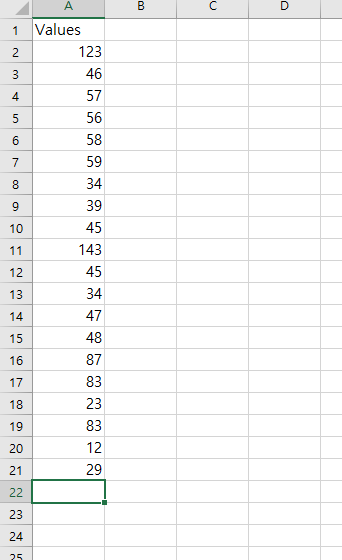
왜도(skewness)는 데이터 분포에 비대칭 정도를 보여주는 수치다. 값은 +또는-일 수 있다. 왜도(skewness)로 분포 모형을 유추하는데 도움이 된다. 왜도(skewness)의 -값은 꼬리가 왼쪽에 꼬리 넓이가 더 크다. 왜도(skewness)의 +값은 꼬리가 왼쪽에 꼬리 넓이가 더 크다. 왜도(skewness)의 0 값은 꼬리가 기울어짐 없이 평균값(mean)에 대칭이다. 구하는 법 =SKEW(array) 함수가 엑셀에 있다. 이 함수는 SKEWNESS = [n/(n-1)(n-2)] * Σ[(xi–x)/s]3 n = 표본 크기 Σ = 합 xi = i번째 데이터의 값 x = 평균 s = 표준편차 엑셀에서 위의 복잡한 식을 함수 하나로 간단하게 계산해준다. 예제 위의 표에서 왜도(skewness)..