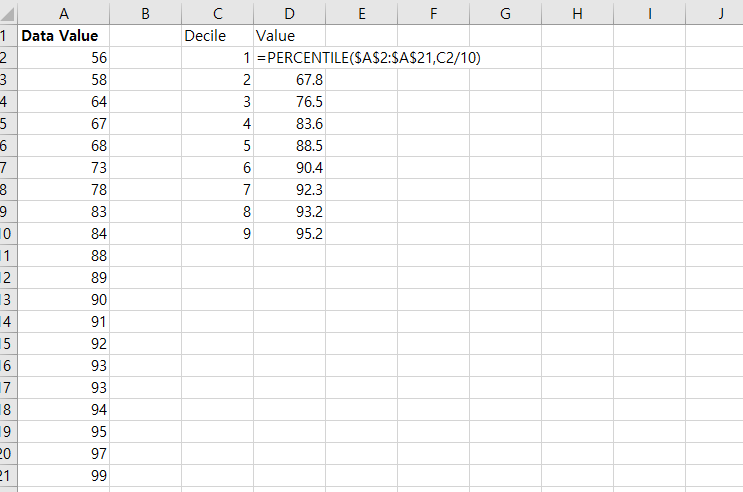
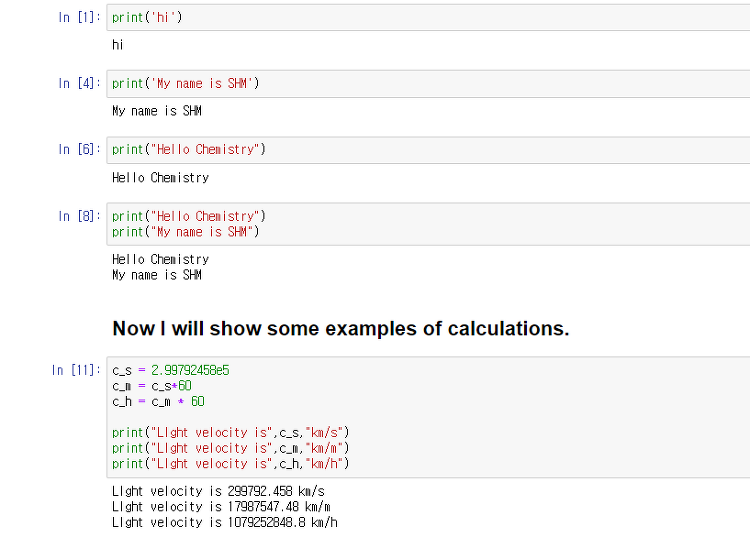
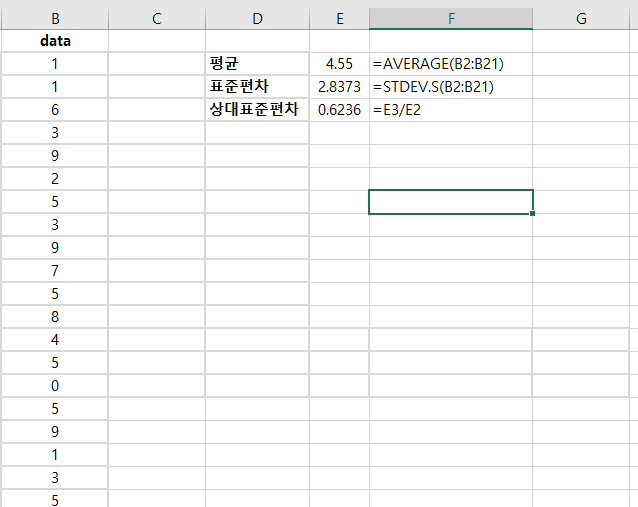
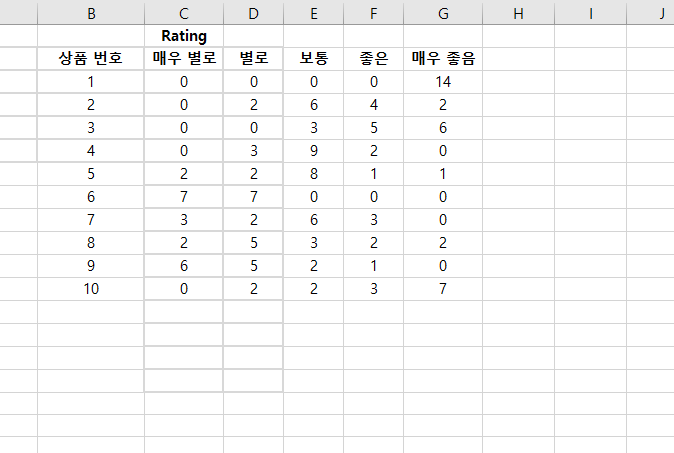
통계에서 Decile은 데이터를 10단계로 그룹화는 것을 말한다. 첫 번째 Decile은 아래에서 10%의 데이터 값을 포함한다. 두 번째 Decile은 아래에서 20%의 데이터 값을 포함한다. =PERCENTILE(CELL RANGE, PERCENTILE) 위의 함수로 Decile을 구할 수 있다. cell range에 데이터 array를 넣고, percentile에 원하는 %를 넣는다. 예시 1: 20%에 데이터는 67.8 아래에 있다. 30%에 데이터는 76.5 아래에 있다. 40%에 데이터는 83.6 아래에 있다. 각각의 데이터의 decile에 넣기 위해서 PERCENTILERANK.EXC() 함수를 사용한다. =PERCENTRANK.EXC(CELL RANGE, DATA VALUE, SIGNIFI..