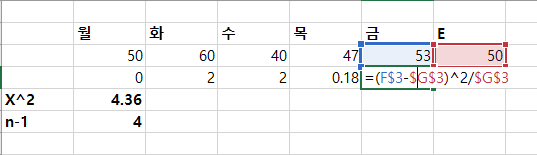
z-점수(z-score)는 통계 데이터 값이 평균에서 얼마에 표준편차만큼 떨어져 있는지 보여주는 지표다. 백분위(percentile)는 관찰 값이 100으로 쪼겠을 때 어디에 분포하는지 보여주는 통계 지표다. 엑셀에 내장된 함수를 이용하면 쉽게 백분위와 z-점수간에 치환이 가능하다. z-점수를 백분위로 치환하기 =NORM.S.DIST(z, cumulative) z = 구하는 값에 z-점수(z-score) cumulative = TRUE 누적 분포 함수(cumulative distribution function); FALSE 확률분포 함수(Probability distribution Function). True로 한다. z-점수 1.78은 백분위로 0.9624와 같다. z-점수 1.78을 갖는 데이터 값은..