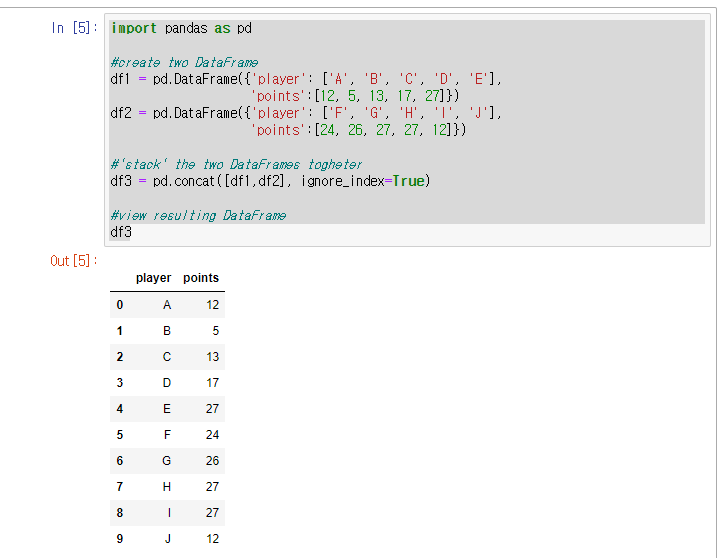
두 개 이상의 pandas DataFrame을 겹치고 싶을 때 concat() 함수로 쉽게 할 수 있다. 이번 페이지에서 cocnat() 여러 가지 활용 예시를 본다 예시 1: 두 개의 pandas DataFrame 쌓기 예시 2: 세 개의 Panda DataFrame 쌓기 ignore_index=True 의미 pd.concat([df1, df2, df3,..], ignore_index =True) 하지 않으면 이전 데이터에 있던 인덱스(index)를 그대로 가져온다. 그렇기 때문에 특별하게 인덱스를 유지해야 하는 경우가 아니라면 'ignore_index = True' 옵션을 추가한다.