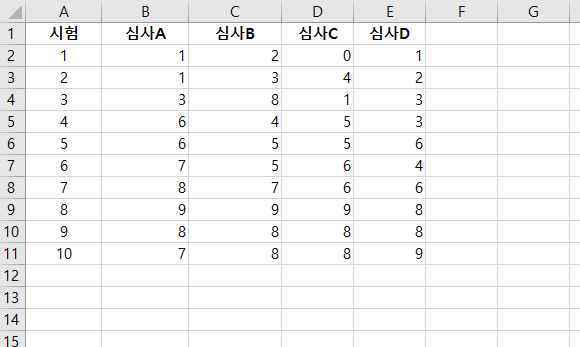
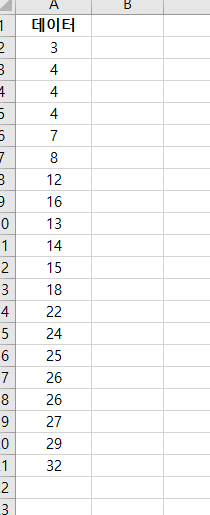
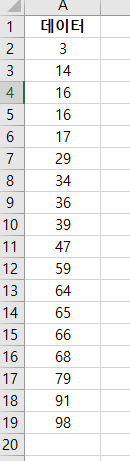
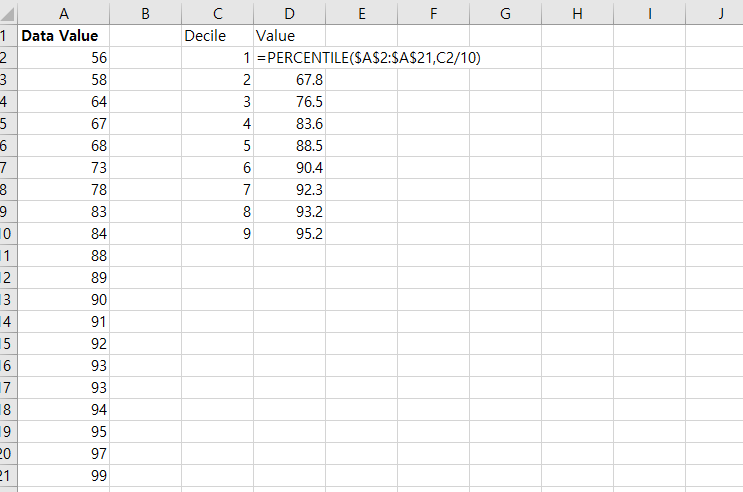
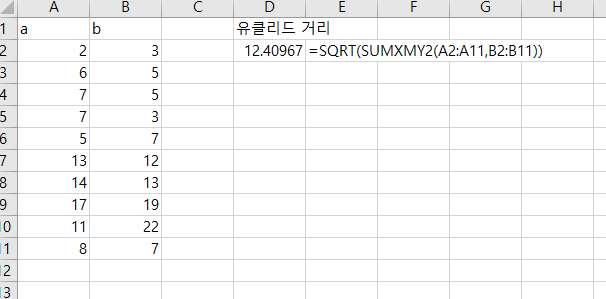
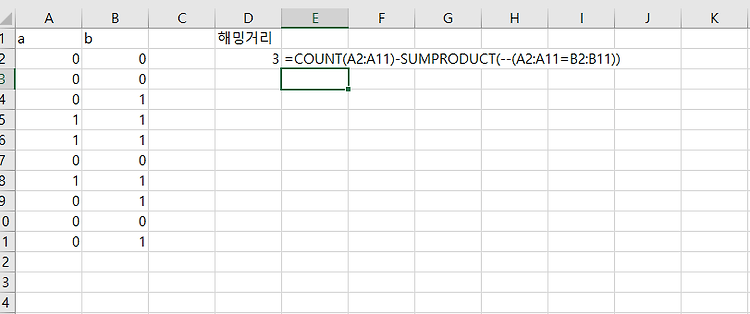
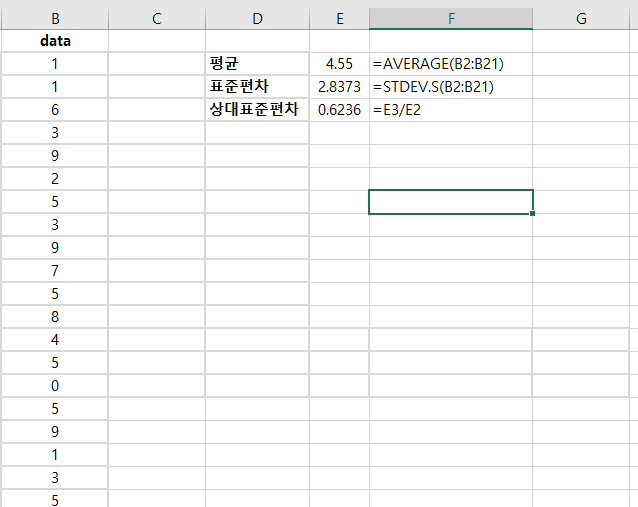
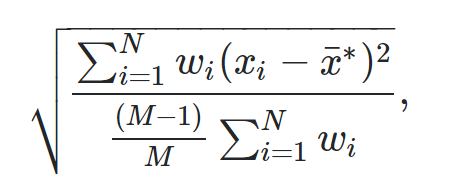합동 분산(pooled variance)은 두 개 이상의 데이터 표본(sample)의 분산에 평균을 한 통계 지표다. 합동 분산(pooled variance)은 두 개 이상의 데이터 표본(sample)의 분산(variance)을 통합해서 공용 하나의 분산(variance)를 의미한다. 합동 분산(pooled variance)은 두 표본(two samples)에 대한, t-test를 할 때 가장 많이 사용된다. (t-test는 표본의 평균이 같은지 아닌지 측정하는 테스트) 합동 분산(pooled variance)는 sp^2 기호로 사용된다. sp^2 = ( (n₁-1)s₁^2 + (n₂-1) s₂^2 ) / (n₁+n₂-2) 어떻게 구하는지 살펴본다. 1단계: 데이터 생성 2단계: 표본크기(sample s..