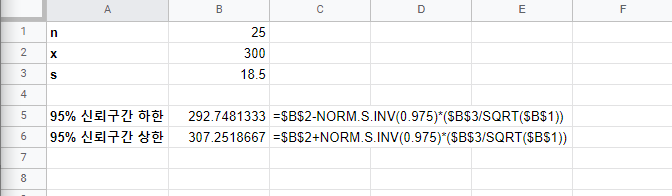
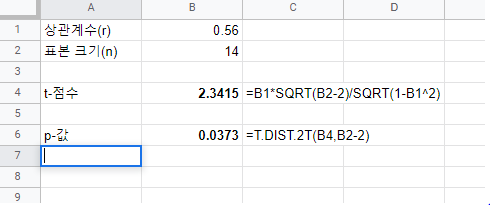
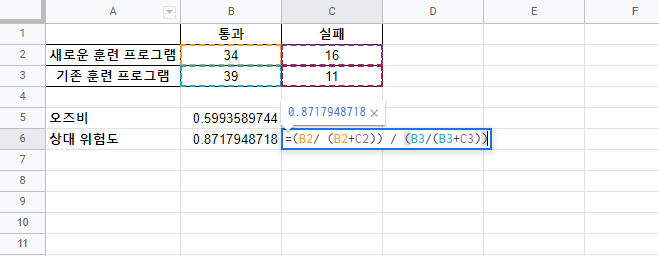
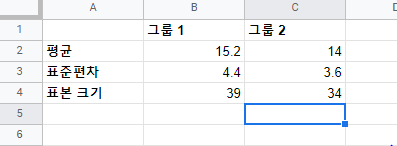
신뢰구간(Confidence Interval) 안에 값은 모수(population parameter)를 포함하고 있다. 신뢰구간(confidence interval)은 아래에 공식으로 계산한다. 신뢰구간(Confidence Interval) = (point estimate) +/- (critical value)*(표준 오차) 위의 공식은 신뢰구간(confidence interval)의 상한 값(uppter bound)과 하한 값(lower bound)을 구한다. 어떻게 신뢰구간(confidence interval)을 구하는지 단계별로 알아본다. 1. 평균의 신뢰구간(confidence interval) 2. 평균차이의 신뢰구간(confidence interval) 3. 비율의 신뢰구간(confidence..