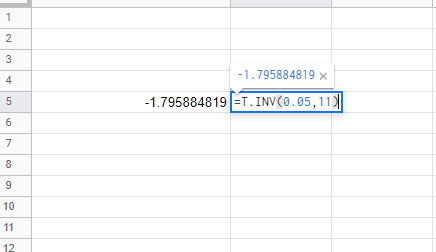
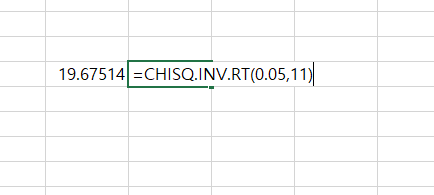
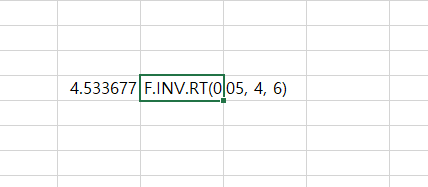
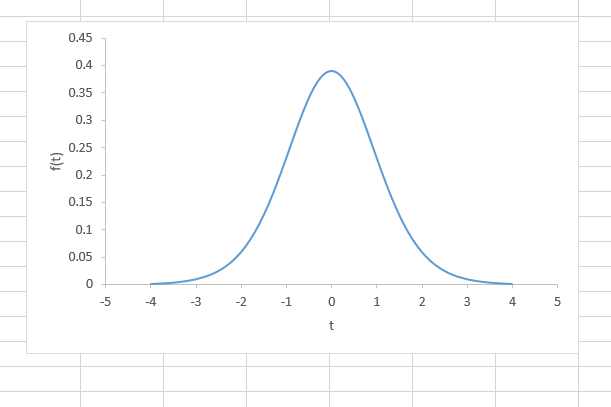
T-검정(T-test)을 할 때 T 통계량을 구한다. 그리고 구한 T 통계량(T statistics)을 T 임계값(T Critical Value)과 비교하여 통계적 유의미성 여부를 판별한다. T 통계량의 절댓값이 T 임계값(T Critical Value)보다 크다면 그 검정 결과는 통계적으로 유의미하다고 한다. T 임계값(T Critical Value) T 분포표(T distribution table)에서 또는, 통계 프로그램들을 통해서 구할 수 있다. T 임계값(T critical value) 구하기 유의 수준(significance level) 정하기 0.01, 0.05, 0.1이 일반적이다. 자유도(degrees of freedom) 테스트 타입(one tailed or two tailed) 엑셀에..